Automatic evaluation metrics are fundamentally important for Machine Translation, allowing comparison of systems performance and efficient training. Current evaluation metrics fall into two classes: heuristic approaches, like BLEU or METEOR, and those using supervised learning trained on human judgment data. Evaluating a machine translation system using such heuristic metrics is faster, easier and cheaper as compared to human evaluations, which require trained bilingual evaluators. In this report, we present our approach to combine multiple automatic evaluation heuristics using machine learning and then compare the quality of translation of two different MT system. Our results show that while each heuristic approach can provide a valid comparison between two system, combining the techniques using our machine learning approach provides higher accuracy.
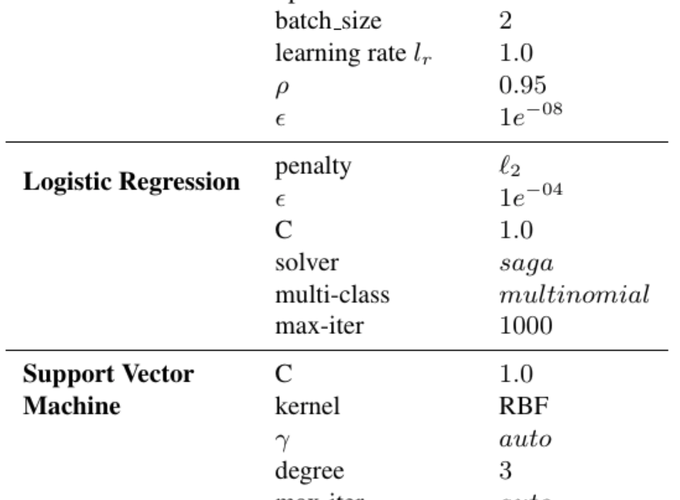
Various hyperparameters used in the classifiers
Anmol Sharma
Engineering Manager, Machine Learning (NLP)
My interests include machine learning, computer vision, medical image analysis and natural language processing.