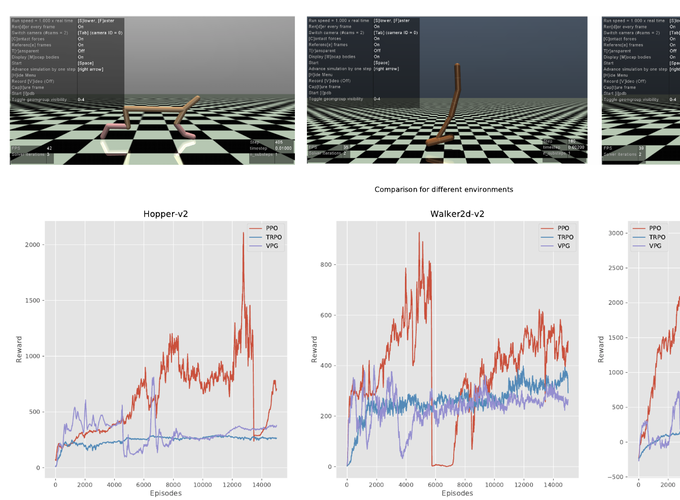
Reinforcement learning (RL) have recently become the framework of choice to develop intelligent agents that can control various entities inside an environment through learning by trial and error. One such task where RL algorithms have been applied is to control simulated robots in a physics-based environment to achieve a set specific goal. These goals can be to run, walk, hop, grasp objects and so on depending on the environment. Recently due to a surge in deep learning (DL) research, RL algorithms have underwent a transformation where many algorithms were revived by utilizing DL methods in some of the internal workings of the RL algorithms. This class of algorithms were named as deep reinforcement learning (DRL). In this project we compare three different DRL algorithms with respect to their ability to control a simulated physics-based robot in an environment. More specifically, we compare Vanilla Policy Gradient (VPG) or REINFORCE, Trust Region Policy Optimization (TRPO) and Proximal Policy Optimization (PPO) algorithms in three different physics-based locomotion environments HalfCheetah-v2, Hopper-v2, and Walker2d-v2 defined in MuJoCo framework ordered by increasing difficulty. Through our experiments, we found the PPO exhibited better performance in all environments in terms of the total reward gained in an episode. VPG performed worse than PPO but better than TRPO due to its simplistic policy gradient approach, though the high variance in training process due to reliance on absolute episode rewards was evident from the experiments. We also observed the TRPO’s convergence is inherently highly predictable, stable, and mostly monotonically increasing, leading to good convergence guarantees but with increased training time.
TRPO, PPO, VPG Agents trying to learn to walk
Comparison of Deep Reinforcement Learning Algorithms for Learning Control Policies for Physics-based Locomotion Tasks
Anmol Sharma
Engineering Manager, Machine Learning (NLP)
My interests include machine learning, computer vision, medical image analysis and natural language processing.